 公司新闻
公司新闻
Triton是由OpenAI开发的一个开源编程语言和编译器,旨在简化高性能GPU内核的编写。它提供了类似Python的语法,并通过高级抽象降低了 GPU 编程的复杂性,同时保持了高性能。目前Pytorch已能做到100%替换CUDA,国内也有智源研究院主导的FlagGems通用算子库试图构建起不依赖CUDA的AI计算生态,截至今日,FlagGems已进入Pytorch基金会生态项目体系。Triton生态内少有CPU架构的实践,且多面向Host-Device的异构方案,进迭时空通过同构融合RISC-V AI CPU技术,结合Triton轻量化的交互式编程模式,将构建起比肩Triton GPGPU的AI高性能编程方案,从而推动AI应用的快速规模化落地。
常见的 Host-Device 的异构 Triton 方案,使得 Triton 算子编程的调试困难,内存模型复杂,不利于开发者灵活的实现自己的想法,而搭建于传统 CPU 之上的 Triton-CPU 方案,也缺乏在AI高性能计算上的硬件支持,例如核内 TensorCore、多核通信与访存优化、多卡互联等。
进迭时空践行的同构融合技术,创新性地在 CPU 内集成 TensorCore,以 RISC-V 指令集为统一的软硬件接口,驱动 Scalar 标量算力、Vector 向量算力和 Matrix AI 算力,支持软件和 AI 模型同时在 RISC-V AI 核上运行,并通过程序正常跳转实现软件和AI模型之间的事件和数据交互,进而完成整个AI应用执行。
基于同构融合 RISC-V AI CPU 架构的 Triton 方案,在编程调试视角看仍然类似于传统 CPU,并且消除了 Host-Device 的概念,采用统一内存,调用侧与执行侧是 Linux 软件多线程的概念,这将极大的降低高性能算子的编程与调试难度。同时,在确保编程易用性的前提下,进迭时空通过集成 TensorCore、紧密耦合内存、Core-to-Core coherence、Cluster-to-Cluster coherence、多核调度优化、AI编译器优化等软硬件创新,处理绝大部分性能优化点,最终交给用户一个上手即用的算子开发工具链。
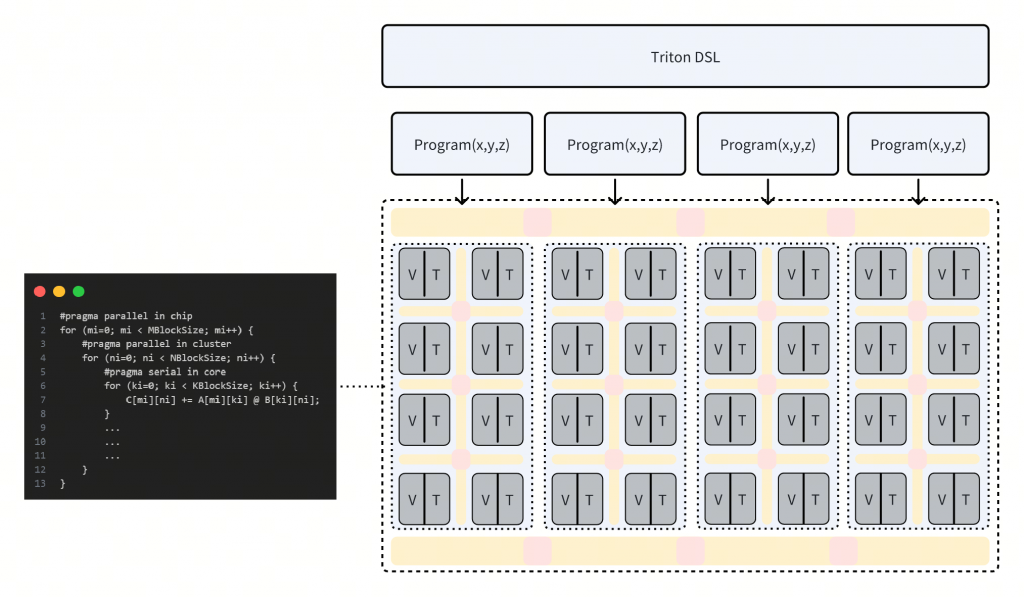
前端层面,支持 Pytorch Triton Kernel 以及第三方 Triton Kernel,例如 FlagGems,支持 Triton DSL 的全部语义。
中端层面,通过 TTIR、TTSIR(Triton Shared)至标准 Linag IR,不做任何 Dialect 扩展。
后端层面,先验调优的矩阵乘 kernel 与 vector.contract 并存,保证矩阵计算高效的同时,释放更多 vector codegen 的可能性。
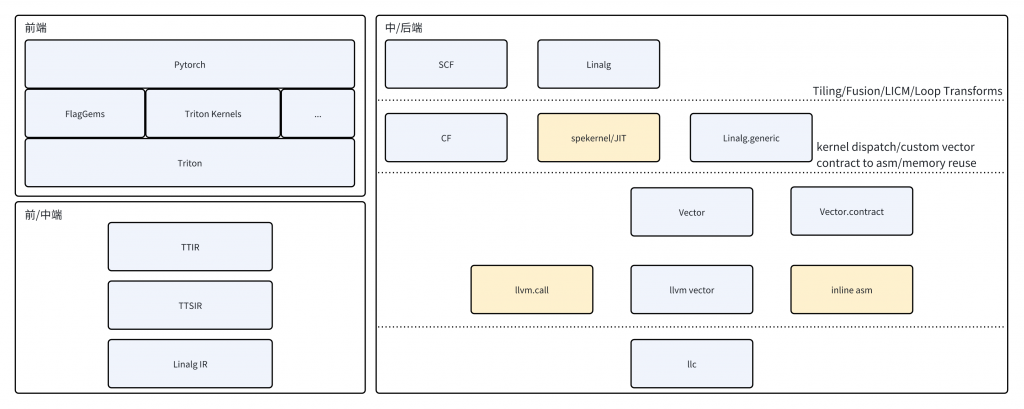
SpineTriton(即进迭时空Triton解决方案)作为 Triton 的第三方后端,对 Pytorch 提供 RISC-V AI-CPU 底层加速,兼容社区已有的Triton Kernel,充分融入现有基于Triton构建的AI加速生态。同时,针对 AI-CPU 核内扩展指令、Core-to-Core 高速缓存、异步访存等特性,对 tl.make_block_ptr 进行了专门特化,开发者在使用 Triton DSL 中的块级访存与计算时,获得更大的优化收益。
前端
以一个矩阵乘的Triton Kernel为例,使用 tl.make_block_ptr 进行访存与计算。
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
# load matmul a and b
a_block_ptr = tl.make_block_ptr(
base=a_ptr, shape=[M, K], strides=[stride_am, stride_ak],
offsets=[pid_m * BLOCK_SIZE_M, 0],
block_shape=[BLOCK_SIZE_M, BLOCK_SIZE_K], order=[1, 0]
)
b_block_ptr = ...
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
a = tl.load(a_block_ptr, boundary_check=(0, 1))
b = tl.load(b_block_ptr, boundary_check=(0, 1))
accumulator += tl.dot(a, b, allow_tf32=False)
a_block_ptr = tl.advance(a_block_ptr, (0, BLOCK_SIZE_K))
b_block_ptr = tl.advance(b_block_ptr, (BLOCK_SIZE_K, 0))
c = accumulator.to(dot_out_dtype)
# maybe some epilogue for c
c_block_ptr = tl.make_block_ptr(
base=c_ptr, shape=[M, N], strides=[stride_cm, stride_cn],
offsets=[pid_m * BLOCK_SIZE_M, pid_n * BLOCK_SIZE_N],
block_shape=[BLOCK_SIZE_M, BLOCK_SIZE_N], order=[1, 0],
)
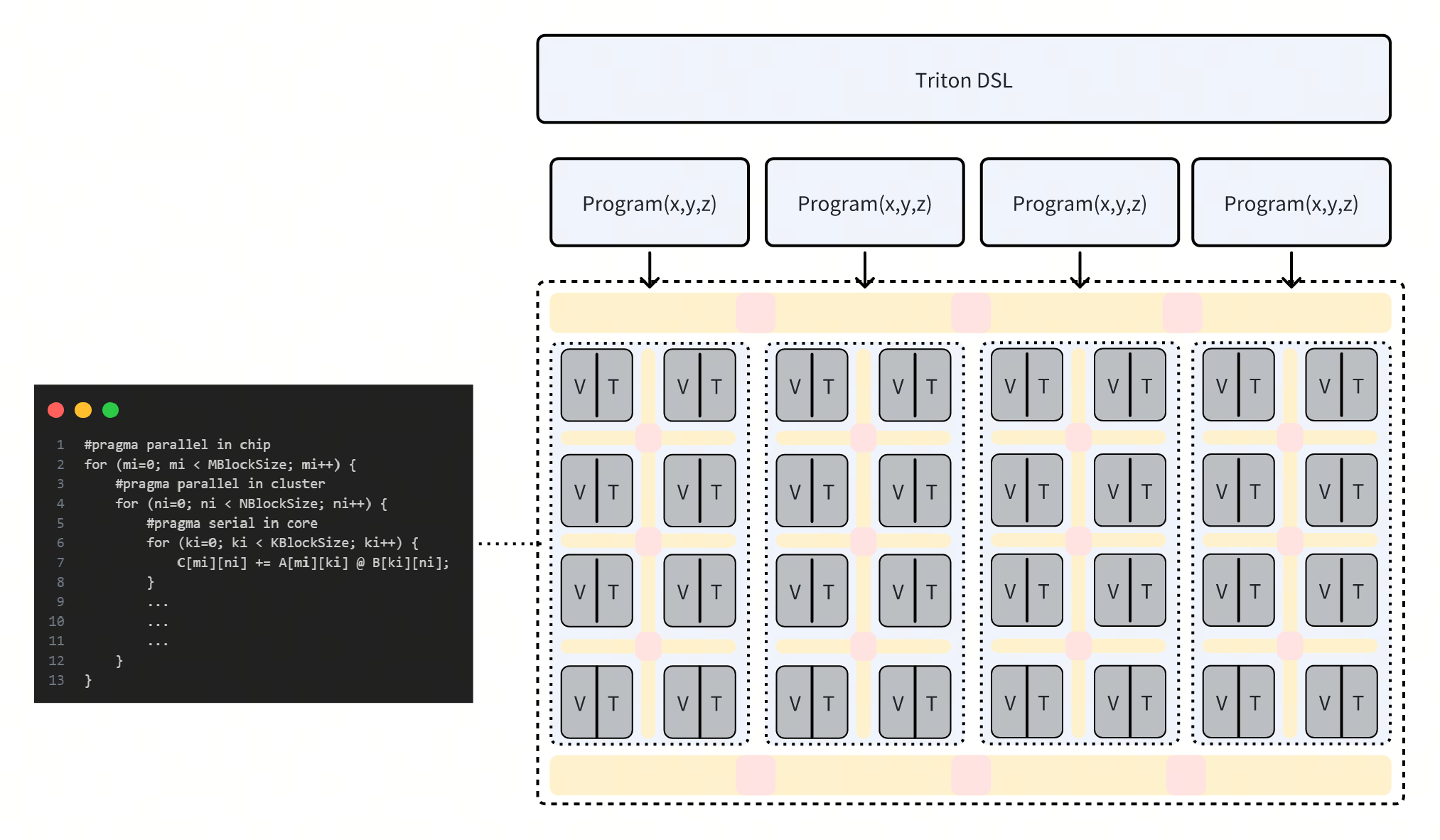
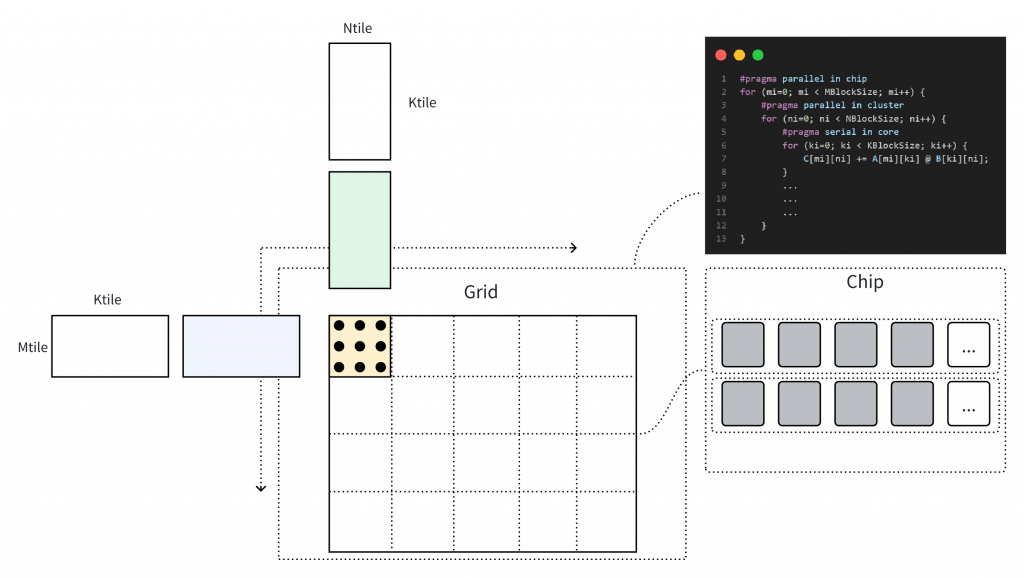
tl.store(c_block_ptr, c, boundary_check=(0, 1))上文 Triton Kernel 描述的矩阵乘计算对应于下图计算过程,当以一个Cluster进行捆绑调度时,SPMD 中的 Single Program 指向一个 Cluster 上的执行程序,通过 Program ID 区分输入与输出数据位置。以开发者的视角看,Cluster 上的编程是线性的,且不需要关心异步数据的访问逻辑,后端编译器将分析用户代码逻辑的潜在并行性,在 Cluster 内完成并行化,以及使用高速缓存合并 Cluster 内多核的访存。
中后端
在矩阵乘内部计算过程的转换时,将完整的 tl.dot 即 linalg.matmul 进行分块分析,充分使用寄存器资源与近核缓存,在中端转为linalg.mmt4d、linalg.pack、linalg.unpack 及结构化循环体的表示。linalg.mmt4d 与手写kernel直接映射并利用到Tensor算力,而其他的算子,则采用affine进行向量化使用Vector算力。
由于采用了 IME 的方式扩展AI指令(参考进迭时空AI扩展指令 Spec,https://github.com/spacemit-com/riscv-ime-extension-spec),在 linalg.mmt4d 这样的 ukernel 的转换过程时,可以直接使用 vector 进行交互,避免在延迟更高的存储结构上进行交互,这是 IME 的一大优点。
// load b
// %acc: vector<16x32xf32>
%0 = vector.load [...] : memref<?x?x32x4xf32>, vector<4x32xf32>
// load a
%1 = vector.load [...] : memref<?x?x16x4xf32>, vector<2x32xf32>
// vfmadot -> 2x8x4 @ 4x8x4 => 2x4x8x8
%2 = vector.contract {...} %1, %0, %acc : vector<2x32xf32>, vector<4x32xf32> into vector<16x32xf32>在 mlir-llvm 的结合部分,通过 vector.contract 构造了大量先验的手写汇编序列,以确保最终性能的可靠性。
Triton 目前仍然是一个 GPGPU 架构主导的 Python DSL 及算子编译器,在 CPU 架构上发展缓慢,仅存在一些在x86架构下的TritonCPU编程的社区工作,且不是最优适配。RISC-V 同构融合 AI 算力的方式,利于打破算子内多种计算模式(Scalar、Vector、Tensor)的隔阂,同时统一内存、统一OS的软硬件架构,使得调试难度降低,系统内多种软硬件资源的交互难度降低。此外,未来也将逐步开源 SpineTriton 的软件栈部分,共同建设 RISC-V Triton 高性能编程社区。


